-
Type:
Bug
-
Resolution: Fixed
-
Affects Version/s: None
-
Component/s: Import/Export
-
High
-
Users who already adjusted the checkboxes, indicating whether some attribute datatype is enabled for some TermCollection - have to redo this
-
TBX import: removed term-level attributes duplicates
-
Emptyshow more show less
1.check why concatenation is not happening on transline
- import the given tbx (imported at 29.11.22) and check what will happen (concat or not)
- what is the difference between TBX Basic and transline's tbx: found - difference in target="..." node-attr
- amend import script logic:
1.make sure that 'target="..."' is omitted so that merging multiple same-level-occurences
(with values concatenation) into single attribute-record in db - won't be prevented
- except datatypes, for which multiple same-level-occurrences is supported (figure, xGraphic, externalCrossReference and crossReference)
- log such cases into TermCollection import-log
2.make sure that unexpected elementName (e.g. tbx node/tag name) for known 'type="..."' will be spoofed with the one expected for such type
- log such cases into TermCollection import-log as well
2.processStatus-duplicates, which can't be because of tbx - another reason, but might be not active
- need to check weekly with a sql query whether duplicates keep appearing: SQL query added to developer-comment for this Jira issue
- if yes, continue investigation
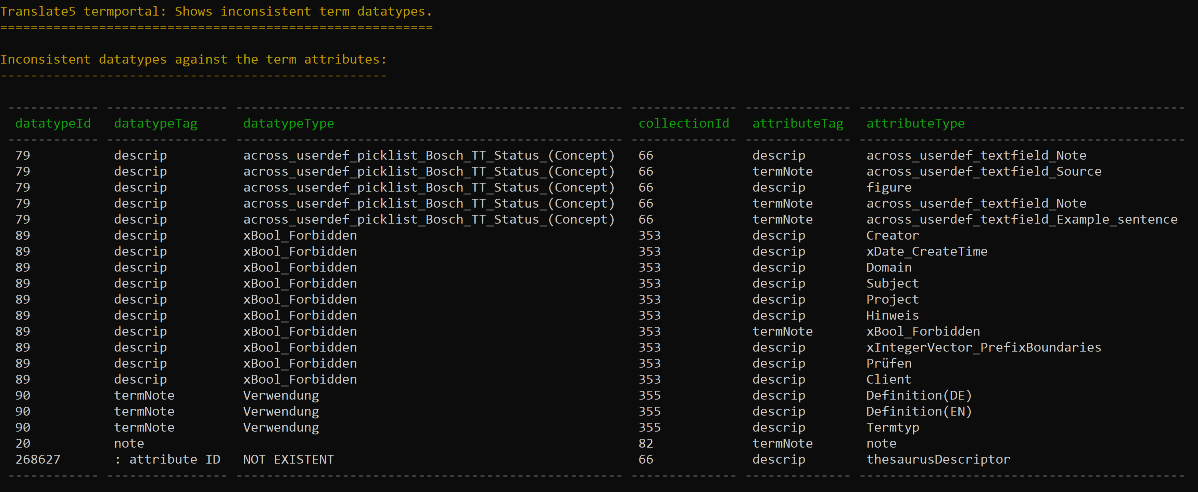
3.same `dataTypeId` but different `type`
- check logic of how new datatypes are created during import: logic added to developer-comment for this Jira issue
- try to import tbx from where such cases appeared previously: not reproducable
4.cleanup-script
- things to fix problem mentioned in point 1.1
- concatenation should happen if all 4 conditions are in place:
- only distinct values should be concatenated
- only for non-picklist attribute datatypes
- only for datatypes, for which multiple same-level-occurrences are not allowed
- only for non-processStatus datatypes
- things to fix problem mentioned in point 1.2
- as long as there might have been tbx-files imported before import script fix released in production,
we may already have datatype-records having same `type` but different `label` and `id`
- for each occurrence detect correct datatype-records and the ones added by mistake
- for all attribute-records having `elementName` and `dataTypeId`
referring to `label` and `id` of datatype-records added by mistake
- spoof `elementName` and `dataTypeId` to refer to correct ones
- delete added by mistake datatype-records
- things to fix problem mentioned in point 2
- delete all duplicated processStatus-attributes except the most recent one for each term
- set termTbxId for term-level attributes where it is null
- things to fix problem mentioned in point 3. Initially @Thomas_Lauria said this should be fixed
manually depending the content of the attributes, but that was about initial approach, based on that
we rely on dataTypeId. New approach is based on that we rely on actual data we have:
- if attribute-record's type is not as per it's dataTypeId, it means dataTypeId is wrong.
- to get correct dataTypeId, we try to find it among existing datatype-records by attribute-record's type
- if found - change attribute-record's dataTypeId and elementName to found one's id and label, respectively
- else if not found
- create new datatype-record based on attribute-record's type and elementName
- change attribute-record's dataTypeId to the newly created datatype-record's id
- add newly created datatype-record to the existing datatypes array used for further search
- collectionId <=> dataTypeId mappings should be updated in the end
- merge levels-lists for datatypes having same `type` but different levels
- append unexpected attribute level to the list of that datatype's expected levels
5.things to be added to checkup-script (e.g. 'translate5 termportal:datatypecheck'-command)
- list of term-level attribute duplicates occurences, having processStatus-ones at the top of list, if found
- list of language- and termEntry-level attribute duplicates occurences
- list of term-level attributes having no termTbxId
- list of same `dataTypeId` but different `type` attribute-occurences
- list of same `type` but different `elementName` attribute-occurences
- list of same `type` but different level attribute-occurences
- list of same `type` but different `label` datatype-occurences
- list of same `type` but different level datatype-occurences