-
Type:
New Feature
-
Resolution: Fixed
-
Affects Version/s: None
-
Component/s: LanguageResources
-
High
-
Add new Re-segment TMX on import feature
-
Emptyshow more show less
Problem
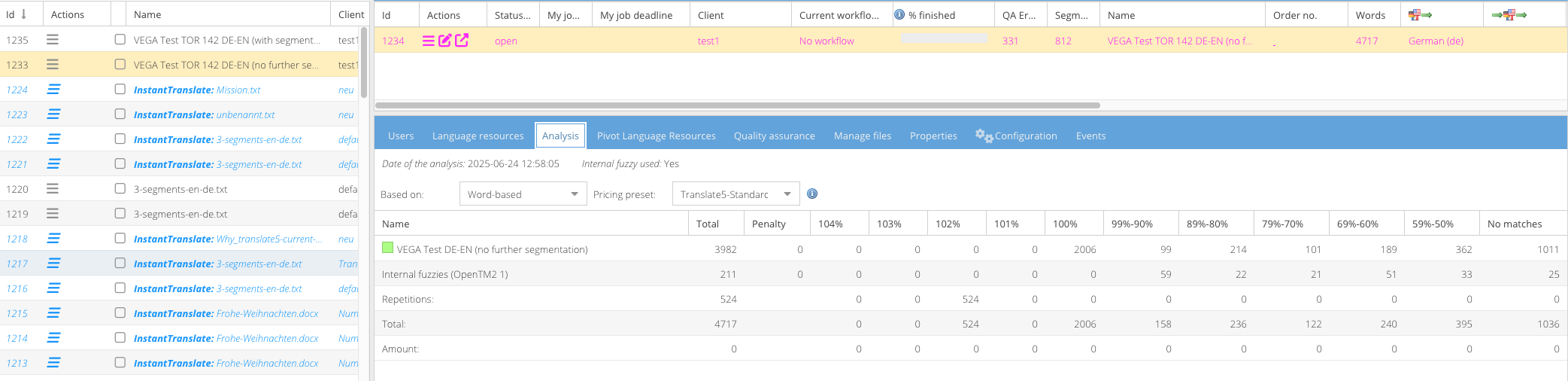
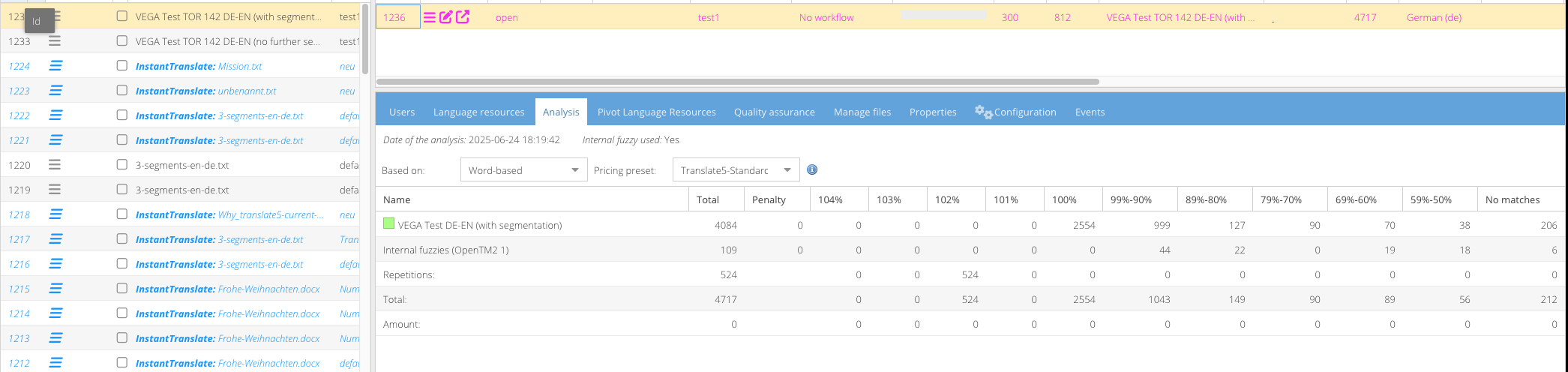
Some TM systems do not segment after every sentence, like translate5 (and most other alike systems) does it. But save one paragraph into one segment, so often multiple sentences.
This leads to a lot of segments not being found or having very bad matches in translation processes.
Solution
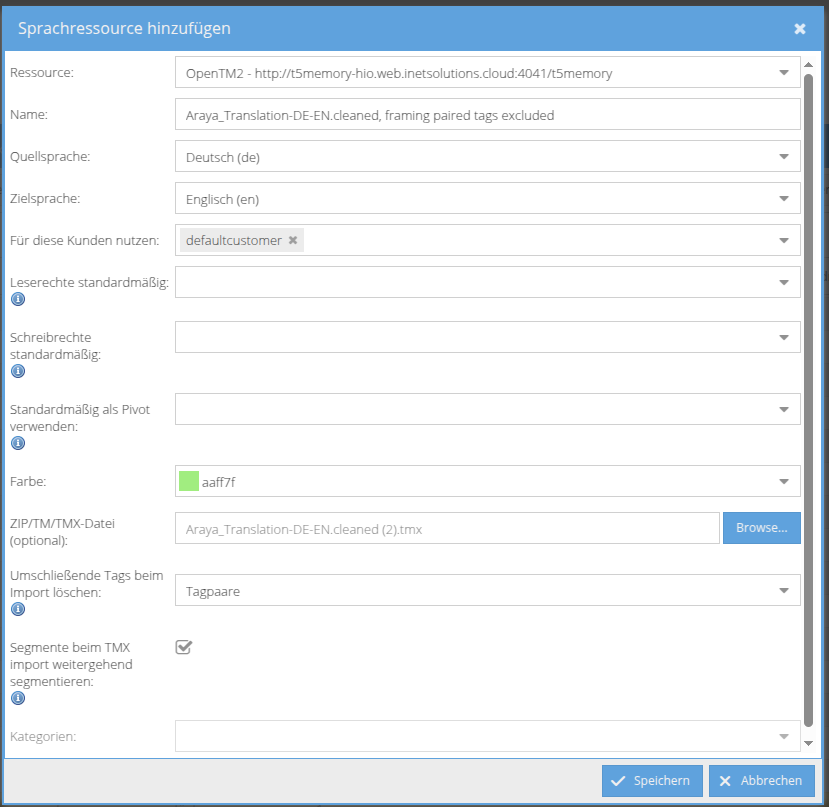
Do a segmentation of each translation unit in the TMX (tu-tag).
Import 1 tu-tag for each resulting segment, if the number of found segments in source and target language is the same.
Import the original tu-tag unsegmented, if the number of found segments in source and target language differs.
Make this configurable in TMX import process in the UI (both for new language resource and for uploading tmx to an existing TM). Default should be disabled, so no further segmentation.
Implementation hint: use the same segmentation mechanism used in InstantTranslate-text-field, so not via Okapi.