-
Type:
New Feature
-
Resolution: Fixed
-
Affects Version/s: None
-
Component/s: LanguageResources
-
Medium
-
-
-
Emptyshow more show less
The feature should be an independent translate5 applet, like TermPortal and InstantTranslate and open in its own browser tab.
For all t5memory language resources there should be a new action icon EN: "TM maintenance" / DE: "TM-Pflege".
It should open the applet and set its filter to browse the currently selected TM.
There should be a new role analogous to the TM-Maintenance (selected clients) role (which is automatically checked, if a user has the role "PM (selected clients) and a TM-Maintenance (all clients) role (that is automatically checked, if a user has the role "PM (all clients).
Please make sure, that the role "PM (selected clients)" is only able to set those TM-Maintenance roles, that are assigned to himself.
Also it should be possible to open the applet from the fuzzy match panel and the concordance search panel of translate5s editor, if the user has the TM maintenance role and the client of the current task is assigned to him (or if the user has the PM role). If the TM maintenance is opened this way, the filter in the applet should be set to filter the segment from which the applet has been opened.
The currently selected filter settings in the maintenance should reflect in the URL hash of the browser. This means, that the current filter set can directly be accessed by the URL, if the current user has appropriate rights to access it.
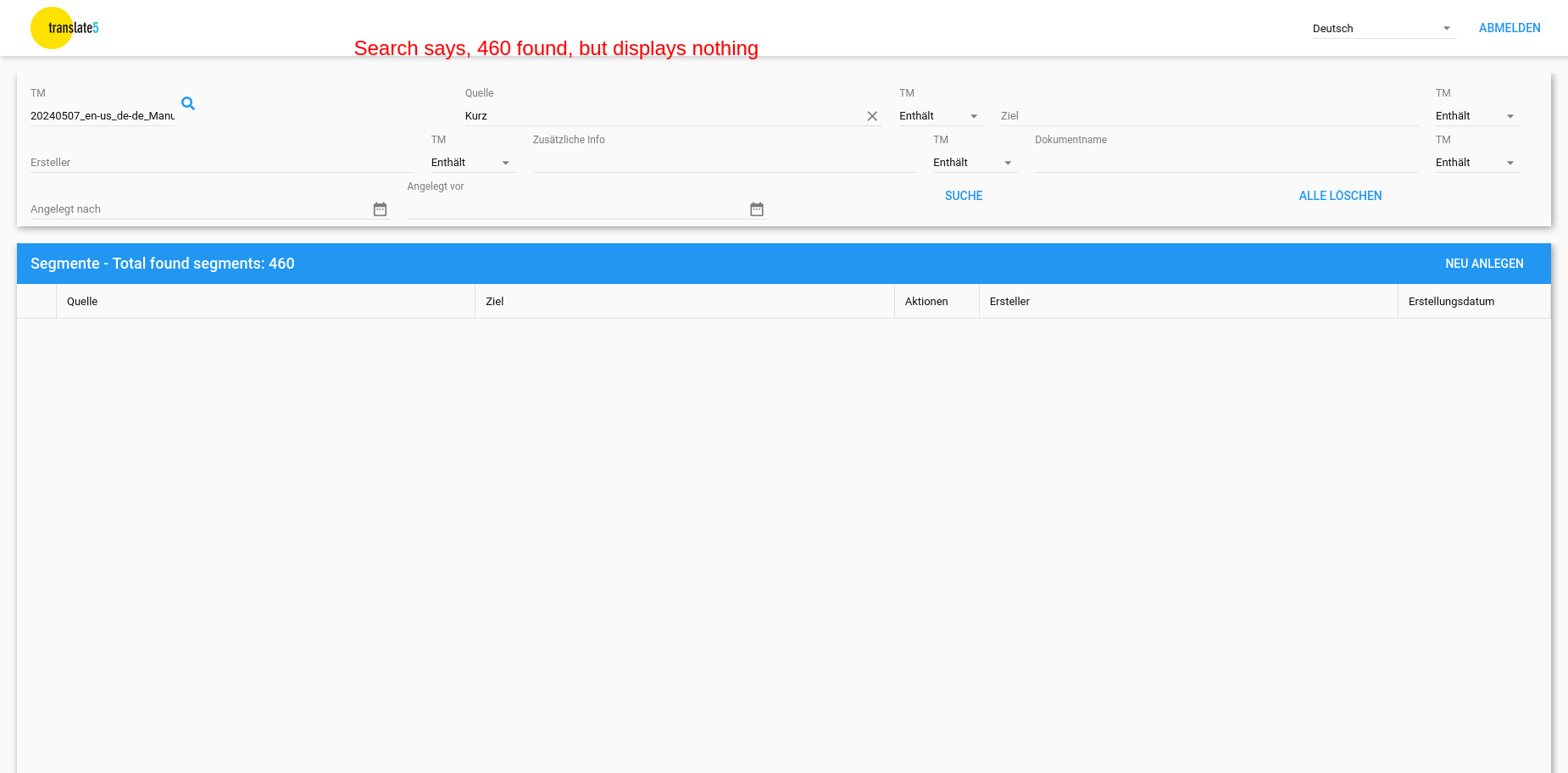
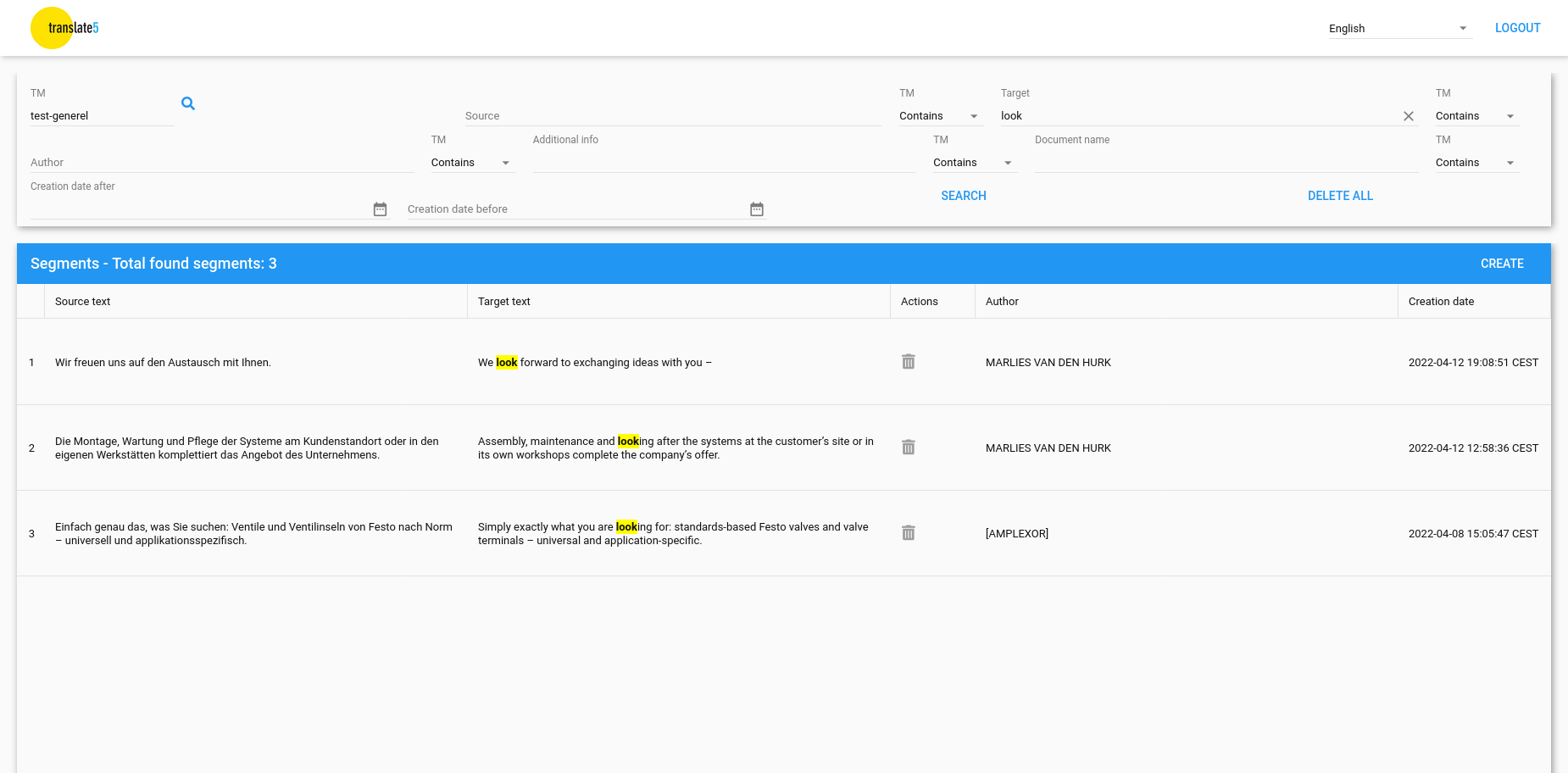
The contents of the applet should list all segments of the current filter set in an endless scrollable grid with the following columns:
- source text
- target text
- author
- creation date
- document name
- additional info
The grid should be filterable along those 6 attributes. By default "document name" and "additional info" should be hidden.
Since we will not make it possible to search through segments of several memories at the same time (as we decided), it must be possible to somehow filter the list of memories by client, source language and target language and by name, in order to select the memory you want to maintain. Because otherwise it will not be maintainable, if you have a lot of memories. So you have to invent a GUI for doing this.
There should be actions to
- add a new segment entry to a TM with the following mandatory fields
- TM name
- source text
- target text
- author (set automatically)
- creation date (set automatically)
- document name (set automatically to "none")
- delete a segment
- edit a segment with the same mandatory fields as for adding a segment, yet TM name can not be set, but has the same value as before
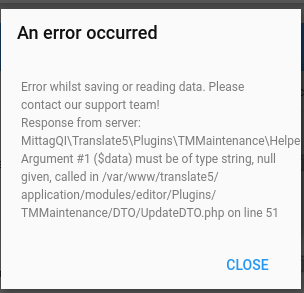
=> with Orest we decided, that we will not implement "update by id" on t5memory side, since this is complex. Instead, when editing and saving a segment in the TM maintenance, we will in translate5 delete this segment by ID in t5memory and then use the usual update call to create a new entry with the change params/contents. And make sure, we set the creation date correctly.
The interface should be responsive, if possible with little effort, for a mobile device layout and work also with touch.
Mass deletion of segments
Orest will implement a new end-point to mass-delete segments:
https://jira.translate5.net/browse/T5TMS-151
After a search has been executed, there should be a button in translate5
DE: Alle löschen
EN: Delete all
with a tool-tip
DE: Alle Segmente die zu den aktuellen Sucheinstellungen passen, werden gelöscht
EN: All segments that match the current search settings are deleted
If button is pressed, a warning should pop up:
DE: ACHTUNG: Alle Segmente der aktuellen Sucheinstellungen werden gelöscht. Wollen Sie wirklich löschen?
EN: All segments of the current search settings will be deleted. Are you sure you want to delete?
If the pop-up is approved, the delete request is fired.
On t5memory-side the request will be implemented in a similar way, as the reorganize. This means, for large memories it will run some time.
This in turn means, that the TM-maintenance has to communicate the user, that the TM is blocked as long as the request in t5memory is executed. This has to be respected everywhere in translate5 analogous to what is done for the reorganize (attention: For the reorganize this must be changed when translate5 switches to usage of 0.5 branch of t5memory, because there the reorganize is implemented asynchronous. This should change should be implemented together with implementing the blocking of TM for translate5 usage while mass deletion, because it is completely analogous. Also TM maintenance features in t5memory will only be available in 0.5 branch of t5memory).
Show number of segments in current search
Orest will implement a new endpoint for t5memory "concordanceSearchNumResults".
https://jira.translate5.net/browse/T5TMS-185
This endpoint will have nearly the same params as concordance search, but only deliver the number of available results.
If search params in the TM maintenance are changed and a search is fired, this endpoint should also be fired a moment after the main concordance search call has been fired (to get the main response first) and its result should be shown above the result list, as soon as it returns (which may take a while for big TMs.)
Enable searching for empty parameters
Searching for parameters in t5memory will be implemented in the way outlined here:
https://jira.translate5.net/browse/T5TMS-82
The way empty parameters can be used there must be reflected in TM maintenance (empty but given parameter means: Parameter content must be empty in search results; not given parameter means: Do not filter the results by this param)
Number of results of concordance search request in TM maintenance usage
Currently the concordance search has a max number of results of 20. Orest will increase this to 200 with https://jira.translate5.net/browse/T5TMS-186. Change TM maintenance to make use of this.
- blocks
-
TRANSLATE-3118 Rework Richtext Editor
- Done